EM•Mark energy efficiency – TI CC2340R5
Our final set of EM•Mark results turns CoreMark inside out: rather than running N iterations of the benchmark in a finite loop, we'll continuously run a single benchmark cycle before entering "deep-sleep" – helping us measure MCU energy efficiency in a more realistic setting.

Program size matters
When comparing the execution time and active power of EM•Mark versus legacy CoreMark, we continually stressed the importance of program size – especially when it enables us to place the entire program in SRAM. How much more so when measuring energy efficiency !!
Applications targeting resource-constrained (ultra-low-power) MCUs often embody a relatively simple cyclic design: wakeup ⇒ execute ⇒ sleep ⇒ repeat .... Needless to say, minimizing the time spent in the first two phases of this cycle helps maximize energy efficiency.
Depending upon the application, this cycle can unfold at rates ranging from once-per-second to once-per-day – with just a fraction of the time spent actively running the program itself within the cycle's execute phase.
The TI CC2340R5 datasheet specifies the following power consumption values for different MCU operating modes and configurations [ @ 3V ] :(1)
- where our sleep phase corresponds to what TI has termed
Standby [ "deep-sleep" ] rather than Idle ["lite-sleep"] mode

While quite competitive when compared against similar MCUs, these power specs in fact tell us nothing about overall energy efficiency; we need to factor in the dimension of time and instead focus on joules / second as the true comparative metric.
To that end, we'll use the (portable) EM•Mark SleepyRunnerP program as our reference benchmark – measuring the total energy consumed over a one-second interval in which the program awakens from deep-sleep and executes the CoreBench.run function exactly once.
The ActiveRunnerP program – used in obtaining prior EM•Mark results – calls CoreBench.run multiple times in succession and then terminates execution; refer to this earlier blog post as a refresher.
We've already seen the impact of an SRAM-based ActiveRunnerP on execution time as well as active power consumption; measuring the energy efficiency of SleepyRunnerP takes our EM•Mark time and power results to an entirely new level.
The envelope, please ...
Using the setup described in EM•Mark Results, the following summarizes the amount of energy consumed when running EM•Mark SleepyRunnerP in different memory configurations:
| EM•Mark | text + const [ Flash ] | 106.4 μJ | 116.3 μJ |
| EM•Mark | text + const [ SRAM ] | 68.3 μJ | 75.2 μJ |
Energy Consumption – [ active / total ]
Using a Joulescope JS220 , we've captured power-profiles of our SRAM configuration (the clear winner here !!) to further reinforce the importance of minimizing active execution time:
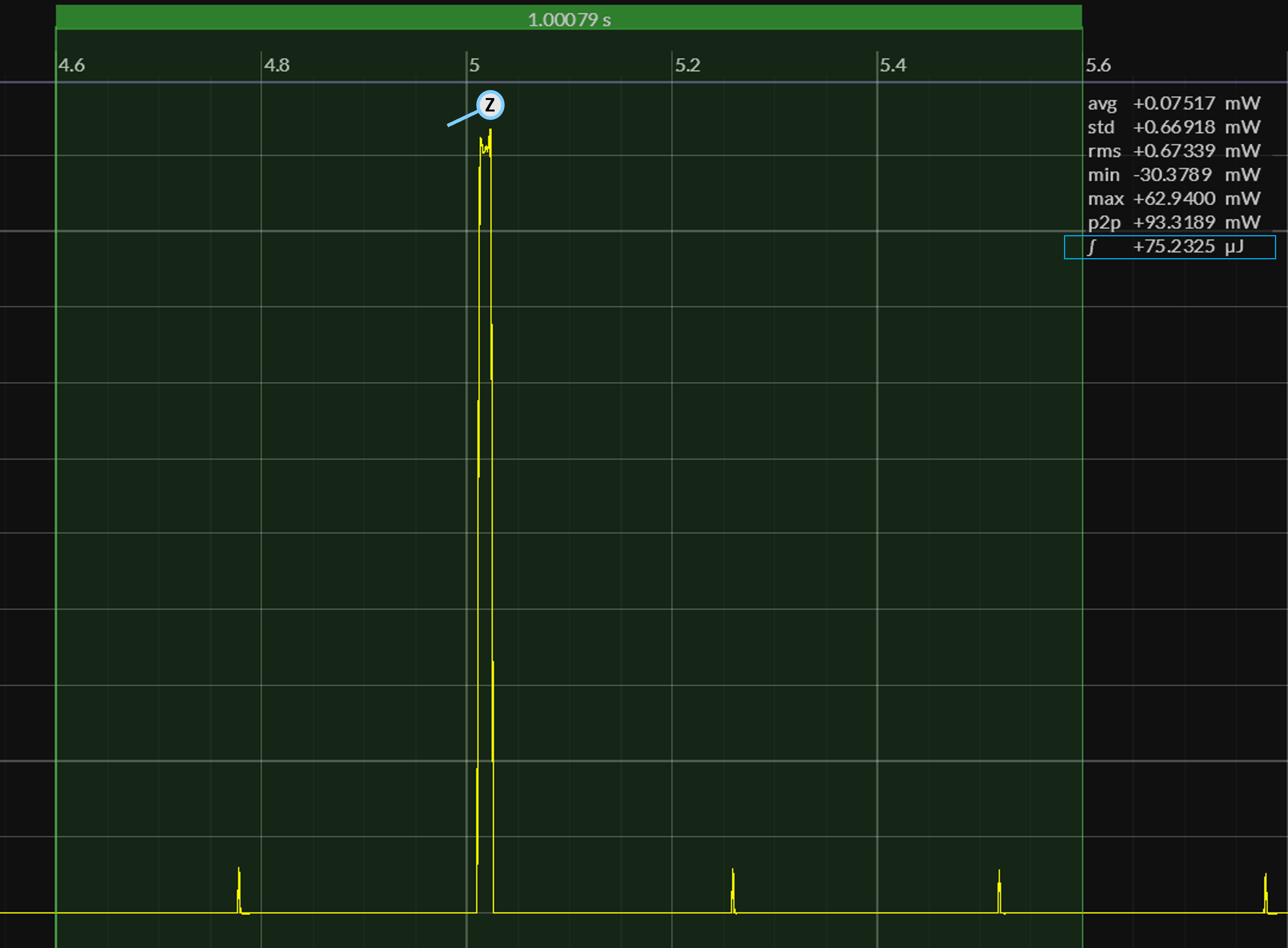
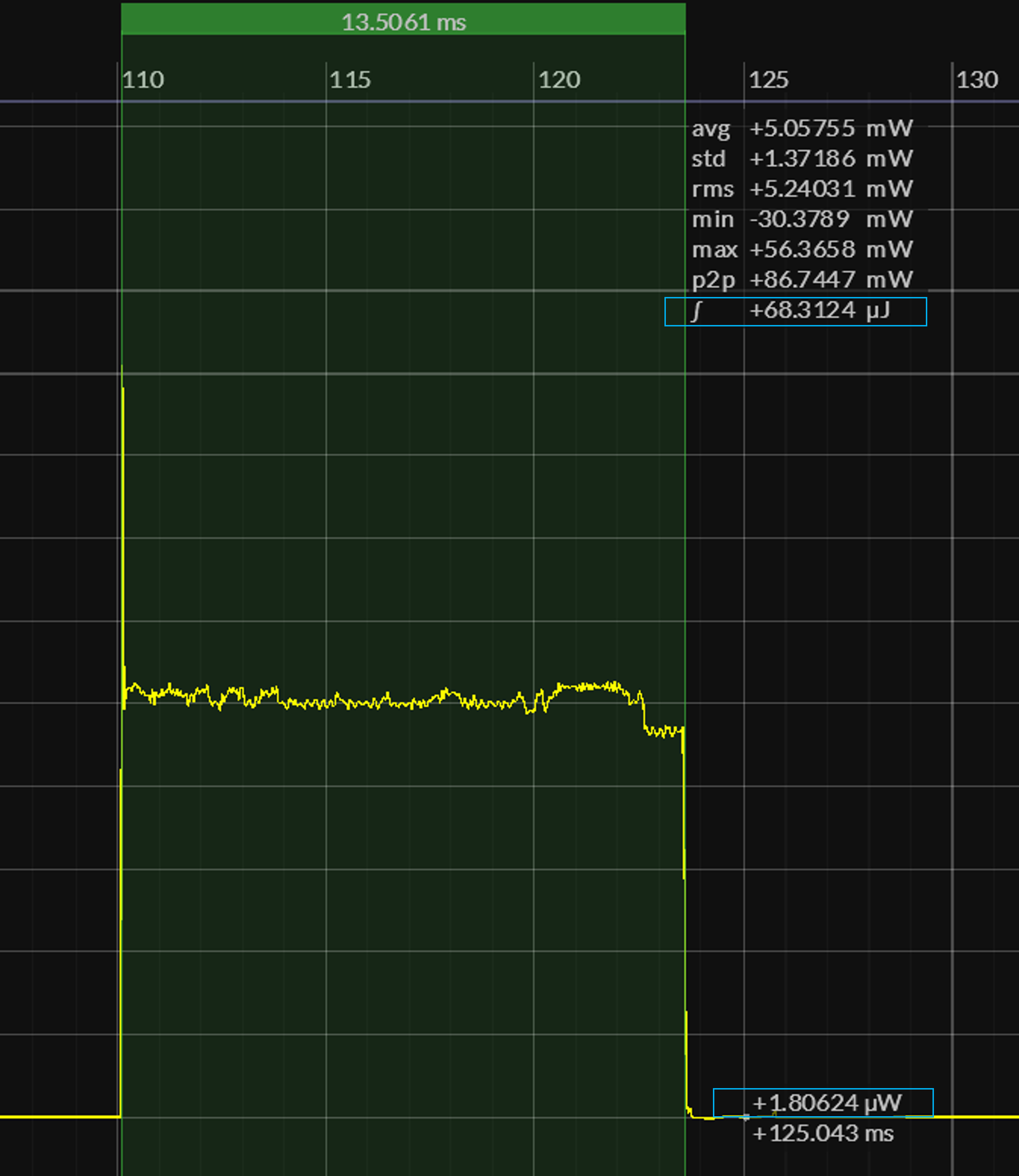
In this case, SleepyRunnerP consumes 90% of its total energy within active execution bursts lasting only 1% of real-time. Once back in the sleep phase of the program, average power consumption then drops to 1.8 μW – in line with the TI CC2340R5 power specs shown earlier.
Prior EM•Mark results covering execution time and active power already anticipate the lower energy consumption of SRAM over Flash when in the execute phase. But what impact does SRAM have on the initial wakeup phase of our program cycle ??
As it turns out, the TI CC2340R5 (like many other MCUs) can preserve on-chip SRAM contents whenever our program enters its sleep phase – supplying only a minimal amount of power to retain the state of memory for the next wakeup.
While typically used to preserve program variables, the very same SRAM can hold program instructions as well – suggesting that wakeup does not require the MCU to power-up the Flash / cache before entering the execute phase.
By effectively using on-chip SRAM as an application-specific cache , our program can quickly "hit the ground running" in the execute phase – boosting overall energy efficiency by lowering response time to wakeup events.
Once again, program size does matter :: less code ⇒ less energy
How can you get involved
consider our Tiny code → Tiny chips premise, in light of the SRAM results reported here
explore this Benchmark configuration material, to understand how we reduced program size
try running SleepyRunnerP with different compiler options – or even with different compilers
Happy coding !!! 
